In programming we often have repetitive, tedious tasks to do. I am lazy, so
I often spend time reducing the tedious tasks to the absolute minmum (I subscribe
to Terence Parr's motto:
"Why program by hand in five days what you can spend five years of your
life automating?"). This often means writing some glue code in Perl or
Ruby or creating some simple ad hoc code generators. Two years ago I've been
using XSLT to generate code from some XML "specification". But I find
XSLT hard to maintain and I have to admit that I am probably lacking the necessary
mindset for a tool like XSLT. Since all my last projects included code generation
in some way, I was thinking about a generalized tool. A tool that might suit
users of Together or Rational Rose as well as those of us hanging on to Emacs
or some such editor. I was looking into XDoclet,
which I found quite impressive (and have used succesfully in some projects).
But although I liked having everything in one place, i.e. Java code and the
additional information for generating other code, configuration files etc. Sometimes
I have the information needed already in some other place, e.g. in a CASE-Tool
repository or a database. So I needed a less restricted environment.
Another thing I do not like is the XDoclet template language (which is going
to be replaced by Velocity
sometime in the future). But I often needed more expressiveness. So when I remembered
a tool called BeanShell, a Java scripting
engine, I considered it the perfect match: Having templates like JSPs that embed
normal Java code which is then evaluated by BeanShell to produce a newly generated
file. Not having to learn yet another language -- even a simple one -- is another
advantage.
But what sort of "model" should I use. The ubiquitous XML again?
What about my CASE-Tool repository or the tags that XDoclet is using? So I decided
to create a representation (a meta model) in Java, that might be filled from
any of these: XML, tags in the source code or any other source that was able
to create either XML or directly create Java objects. This representation should
at least contain classes and fields, and should be very extensible.
So Codex is an environment that allows to generate
code from a "model" using templates.
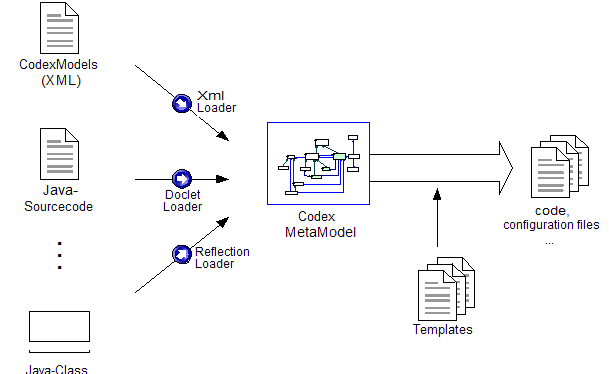
The following figure gives an overview over Codex:
Fig 1: An overview of the Codex
code generation
Codex "Hello World"
Before going into the details I want to start with a simple example, a Codex
"Hello World". The simplest model (in the Codex
XML format) consists of a single class with no fields and no operations:
<model>
<class name="Hello"/>
</model>
Now let's generate a corresponding Java source file using the following template:
public class ${clazz} {
}
If the model is in "model.cml" and the template in "simple.ctl"
Codex can be invoked on the command line with:
$ codex -m model.cml -t simplest.ctl
and the output should be:
public class Hello {
}
So ${clazz} has been replaced by "Hello",
the name of the class by implicitely calling clazz.toString(). Everything between
${ and } will be evaluated as an expression and the result will be written to
the output stream. The clazz object is the
central object for every template. It is a global variable made available to
the template by Codex. With the above command
line invocation, Codex executes the given template (simplest.ctl) for each class
in the model file, each time setting the global variable clazz to a new value.
Since there was only a single class in the model file, the template was only
invoked once.
Since the above example was so simple and the result could have been achieved
easily with XSLT. Let's look at a slightly more interesting example. The following
code fragment might be from a simple data access layer:
It fills the parameter of an update or insert statement using the data from
a ValueObject. For each database table and each corresponding ValueObject, the
code is structurally the same. So this might be a godd candidate for code generation.
The template for the above code might look like
public void bindArguments ( PreparedStatement p, ValueObject vo ) {
...<%
int pos = 1;
for ( MetaField aField : clazz.getDeclaredFields() ) { %>
p.set${aField.getType()}( ${pos++}, vo.get${aField.getName()}() );
<% } %>
}
In the above template fragement we are iterating over all field declared in
the clazz object (clazz.getDeclaredFields())
using the new Java 1.5 syntax for iterating over collections. The rest is quite
straightforward (if you know JSP). But to be able to write new templates, it
is surely necessary to know the Codex metamodel.
Luckily Codex comes with an Eclipse plugin that
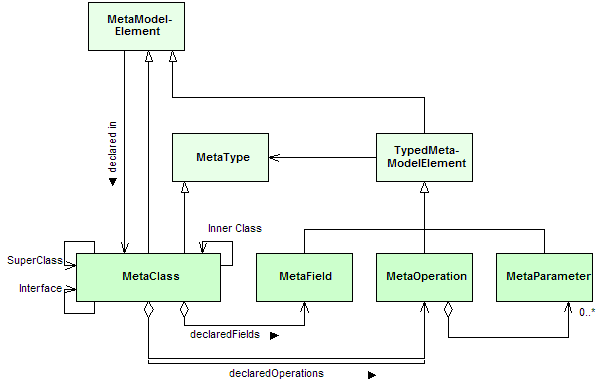
has code completion in these templates. But a look on the metamodel now, might
help anyway:
Fig 2: An overview of the Codex
MetaModel
There are similiar models like the Eclipse Modeling Framework (EMF)
or the XML Metadata Interchange (XMI)
specification of the OMG. I considered to use one of these existing models,
but they both seemed much too complicated for me. The EMF was only in its infancy
when the first version of Codex has been developed and I must admit that the
"Not Invented Here"-Syndrome might have started to set in here, too.
Starting from the global clazz object all fields, and operations declared in
this class (as well as the inherited ones) can be accessed. They also could
be manipulated but generally retrieving information from the previously loaded
model should be sufficient for code generation. But often the information in
the model might not be sufficient for the task at hand. For the previous example
of a simple data access layer, it might be necessary to add the table and column
names to the model. Therefore Codex provides
a mechanism to add information to any element in the meta model. These additional
informations are called "Annotations" (following the JSR-175).
An annotated model (using again the Codex XML
format to specify the model) could then look like this:
If more complex annotations than simple strings are needed, names like "db.table",
"db.primarykey" etc. as in Java property files can be used. But Codex
is also able to create (and load) complex objects (see Annotations
And Aspects
).
Metadata based Code generation
The following shall put Codex into context:
What other tools I am aware of, what I think about MDA (is Codex
MDA?) and when Codex or any other code generator are not to be used. If you
are mainly interested in using Codex just skip the following and goto Using
Codex
.
Model Driven Architecture
First, I must admit that I do not like the name "Model Driven Architecture".
But from the OMG point of view Codex
might be considered as an MDA tool: It creates code from a model. The model
must not necessarily be a UML model, but a XMI-Loader is currently developed.
Codex does no model to model transformation,
there is only a single step from model to code, but anyway, the concepts are
not too far away. So why don't I like the term MDA? One thing I fear is the
hype that currently (as of 2003) surrounds MDA, it's big promises. Another is
the name in itself, my notion of "architecure" seems to differ from
the OMG's notion. For me, architecture means a high level view of the system.
If I have to explain a software system to a new colleague, the architecture
is the structure of the system I draw on a sheet of paper, so he has a frame
of reference, when he is lost in the details. (That also means that the "architecture"
depends to a certain degree on the person I am speaking to, see also Fowler
(2003)). Figure 1
might called the architecture of Codex. But a
model used in MDA must be much more detailed, so I could perhaps live with "Model
Driven Development", but then again any term that contains "driven"
makes me feel lead by the nose.
XDoclet, EMF, etc.
There are other tools doing similiar stuff, e.g.XDoclet, EMF, ArcStyler, CodaGen,
b+m generator framework, XCoder, AndroMDA etc. If you know any of the tools,
please tell me what you conceive as their major benefits (or problems).
I can just tell how and why Codex has been developed.
Some of the tools I have not even heard of when I started implementing Codex
in early 2003. And tools like ArcStyler or CodaGen are quite heavily priced,
so I do not consider them here either.
XDoclet: As
I said in the first chapter: I like XDoclet. When I would not want to create
my own templates, I could stick with XDoclet. But I do not like their template
language. Even the XDoclet developers seem to dislike it now and want to replace
it by Velocity. But in early 2003 I did not know of any plans moving to Velocity
as template language. The other thing I see as a disadvantage is their using
of JavaDoc tags as only mechanism to load the XDoclet meta model. AndroMDA
provides a mechanism to get from UML models to the XDoclet meta model, by creating
code with XDoclet tags. But again I end in XDoclet land.
Eclipse Modeling Framework (EMF):
I consider EMF as the heaviest contender. When I asked them early 2003 if they
would have a template language, to be able to generate any code and not only
the code EMF generated out of the box, the answer was not very promising, but
in autumn they had the Java Emitter Templates (JET), which is very similiar
to what Codex does. And they already have XMI
import. So if you like Codex have a look at EMF.
b+m generator
framework: Became Open Source late in 2003. They are much more
based on the OMG MDA concept, e.g. using a real UML/MOF meta model. The template
language is homegrown and has support by the company that originally developed
it. We have to see what happend to the code.
When not to use Codex (or any other code generator)
Using any code generation tool comes with a certain price. In the simplest
case, you must learn to use the tool, learn how to write a Codex
model file (in XML), or a CASE tool and the additional tagged values, sterotypes
and marker interfaces used by the code templates (see TODO). This works reasonably
well if all you want to generate is some EJB code and the necessary deployment
descriptors. The target domain is well understood, there are not too many corner
cases to be expected, that the templates won't generate well. You won't have
to adapt generated code, or use some barely documented extension points of the
generated code.
But if you have to write your own templates, you have to invest some hours.
You have to learn the template language and the API of the meta model. But this
is quite simple. The real challenge is the target or application domain. Do
you have enough experience of the target domain? Do you really know what can
be generated and which extension points must be offered? There are books on
domain engineering or product family lines (TODO) that might help you with this
task. But anyway, even if you succeed, did you invest more time into the code
generation than it would have cost you to implement everything by hand? If yes,
will you use the templates in the following projects, and later regain some
of the investement in the templates? Can you simply adapt the templates to new
needs and regenerate the code?
My advice: use existing templates for a well known application domain and leave
the rest to nerds like me. Ok, we will have all the fun, but you will have a
running system.
Using Codex
Template language
The template language is basicially like JSP. Java Code embedded in static
text. The parsing and transformation is therefore quite simple. Java Code between
"<%" and "%>" will be left as is (with the "<%"
and "%>" removed). Java Code between "<%=" and "%>"
will be evaluated as expression and written to the output stream. Instead of
"<%=" and "%>" you can also use "${" and
"}". The code can be any legal Beanshell code, which is nearly equivalent
to normal Java code (for the exceptions and enhancements, e.g the Java 1.5 for
loop see www.beanshell.org).
The rest, the static text will be wrapped in double quotes and written to an
output stream. If the template
public String toString () {
StringBuffer buf = new StringBuffer();<%
for ( MetaField aField : clazz.getDeclaredFields() ) { %>
buf.append(<%= aField.getName() %>).append("\n");
<% } %>
}
is parsed and transformed by Codex, it will
result in something like:
The doc variable is roughly the same as the
output writer object in JSPs. It is normally initialized to stdout, but can
be changed by the @document pragma (see below). In a big project with many classes,
such a template might get used quite often. Since the templates will be interpreted
by Beanshell at runtime, this could become quite slow. But if the template is
wrapped in a function declaration and then only the function will be called
for each execution, Beanshell is much faster. It has to parse the function only
once, and keeps a representation of the parse result. So in reality the transformation
result will look like:
The DocumentFactory is used when the output shall be redirected to a file .
If anywhere in the template the @document pragma is used, the output will be
redirected to the file given after the pragma:
<%@document "Foo.java" %>
This pragma can occur multiple times in the template, thereby creating multiple
files from a single template. This is often useful, e.g. if the a ValueObject
class shall be created that is used by some other generated classes. If everything
is in one place it is easier to keep it all consistent. And perhaps, some complicated
calculations have to be done only once. On the other hand the template might
get too complicated. So it is -- as so often -- a question of balance.
When the output will be redirected to another file, the previous file will
be closed and post processed for formatting (see TODO).
As said before the language supported by Beanshell is nearly like Java. One
notable exception is the source command, that
evaluates the content of the given file. As far as Codex is concerned, this
is equivalent to including the content of file in the template. But there are
some technical caveats that are important for the usage of Codex
as part of an IDE like Eclipse. The reasons are quite difficult to explain (see
Codex Eclipse Plugin
), so here it should be enough to state that instead of the source
command, the @include pragma should be used:
<%@include "base.ctl" %>
There currently is another pragma, the @import pragma. But it is still and
I would advise against using it yet. It is used instead of normal import statements,
which can be placed anywhere as far as Beanshell is concerned. But for code
completion purposes (see Eclipse Plugin
), Codex tries to create a valid Java source
file. So the import statements have to be moved outside the actual template
code and to help Codex find the import statements,
the imports should be declared using the @import pragma:
The import statements may still be placed anywhere. Still: if the Eclipse will
be able to handle import statements anywhere, this pragma will be deprecated
(but still supported).
Post processing
One of the reasons, some people dislike generated code, is the format (indentation,
etc.) of the generated files. It nearly never matches the coding guide lines
and/or the templates look very strange to achieve a result that roughly resembles
the coding standards. Codex therefore has an
integrated post processing step, that formats files (depending on their suffix,
e.g. ".java") with a post processor. This post processor might be
configured, and it should be easy to adapt any formatting tool, so that it can
be used with Codex. Codex
contains the powerful Jalopy code formatter
(which unluckily became commercial at the end of 2003, but the version that
is coming with Codex is still open source (BSD) and the best formatter that
I am aware of). If another formatter shall be used with Codex,
the post processor must implement the following interface:
publicinterface PostProcessor {
/**
* Reads the given file and generates an output file if
* the PostProcessor is responsible for files that have the suffix of the given file.
* Beware the fileIn and fileOut may be the same. The PostProcessor itself has to
* check for this condition. The PostProcessor may choose to keep a copy of
* the original file in this case but does not need to.
*
* @param fileIn
* @param fileOut
*/publicvoid process(String fileIn, String fileOut);
/**
* Makes the PostProcessor responsible for files that have the given file suffix.
* @param suffix -- the file suffix that this post processor is responsible for, e.g. "java".
* do not include the first "." (dot). If ".java" is added then only files like "foo..java"
* shall be processed
*/publicvoid addSuffix(String suffix);
}
}
And then Codex must be told to use this formatter for certain files. In the
Codex configuration file Jalopy is configured
as post processor for files that end with ".java":
We had quite some discussions on what to call these items: attributes, properties,
tagged values, etc. But none of them were sticked (they were used in other contexts,
e.g. "property" for JavaBeans or were not intuitive, like "tagged
values").
MetaClassLoader
Initializing Codex
Codex is initially configured by
an XML file. You can configure which Loaders shall be used, or which post processors.
For each Loader you can define which model files and/or directories will be
loaded, etc. A sample configuration file might look like this:
Let's go through all elements step by step (The root element is
always "codex"):
<outdir>
This element defines the global output directory. Every file
generated with a relative path (see @document)
will be created below this output directory
<model>
Codex contains a (singleton) model, which will be configured by the following
elements
<loaders>
To load MetaClasses, the model uses a list of Loaders(see MetaClassLoaders
). When a class is not already loaded, the model asks each configured loader
to load the class. The order in which the loaders are asked is determined
by the order of the XML elements. In the example above, the XmlLoader will
be asked first and then the ReflectionLoader (see also TODO).
<loader>
class=
The fully qualified name of the class to be used as Loader. The class
has to implement the MetaClassLoader
interface and must have a no-args constructor
path=
The path attribute defines the "classpath" of the Loader, i.e.
it is the list of files and directories, where the Loader should look for
model files. (For a discussion on the search algorithm used, see TODO, but
it is roughly equivalent to that of a normal class loader)
alias=
The alias attribute is used to reference configured items by a global
name, e.g. by the Aliases (below)
<post-processors>
The postProcessor element defines classes that are used to post process
code (any files) that are generated by Codex, eg. to format and indent Java
Code (see Post Processing)
<post-processor>
class=
the class attribute must contain the fully qualified class name of the
post processor
suffixes=
the suffixes attribut must contain a comma separated list of suffixes,
for which this post processor should be used. It is thereby possible to
have different post processors for XML and Java.
alias=
The alias attribute is used to reference configured items by a global
name, e.g. by the Aliases (below)
<aspectories>
Aspectories are Factories that are used to create complex annotation objects
(see Annotations and Aspects)
<aspectory>
class=
the fully qualified class that should be instantiated as Aspectory
(must have a no-args constructor)
alias=
The alias, which can be used to later reference the installed aspectory
e.g. from the Aliases (below)
If the existing loaders, post processors and (most likely) aspectories are
not sufficient and added to the configuration file, they must be added to the
CLASSPATH. The batch (shell) scripts use a simple mechanism (also used by Ant):
just copy the jar file to the lib directory of your Codex
installation and the jar file will be automatically included in the CLASSPATH.
(For the Eclipse plugin ... TODO)
The additional components might be configured using the default codex configuration
files if they comply with some simple conventions. The component must be a Java
Bean, i.e. for each property that should be configured by Codex, there must
be a setter (or a getter, if the property is a collection). Let's say, we have
implemented a new Loader that uses a database as source. It has the properties:
ConnectionString, User and a Password. The configuration could then look like:
Attribute and element names are transformed automatically to valid Java property
names (all "-" will be removed and all characters after a "-"
and the first will be transformed to upper case). So Codex
will first instantiate the class sample.DbLoader and then call setConnectionString(),
setUser() and setPassword() with the appropriate values. If the property is
not a value type (String, Date and all primitive types), an XML element instead
of an attribute must be used and the element must contain a "class"
attribute. So if we want to add multiple connections, the configuration file
should look like this:
For the above to work, there must be either a method getConnections() that
returns a collection or a method called addConnection(ConnectionInfo). The latter
is a deviation from the standard JavaBean specification which simplifies the
implementation of collection properties (see also Codex
Model Files
).
Default Initialization
(TODO)
Aliases (command line)
The initialization by a Codex configuration
file is quite basic. Often, a certain models shall be used for an invocation
of Codex, or only a single class (of all loaded classes) shall be used for code
generation. This can easily be done by the command line. In the above section
we saw that most configuration elements contained a n "alias" attribut.
Using this attribute the configured object can be accessed later (even from
the command line).
In the above example, the XmlLoader was given the alias "xml".
When the loader shall later be retrieved, the following code can be used:
If the model file "MyModel.xml" shall be loaded by the XmlLoader,
the command line must look sonething like:
$ codex.sh -m:xml MyModel.cml ...
This works well for MetaClassLoaders that are known to Codex in
advance. But what about a new MetaClassLoader (post processor, Aspectory, ...),
that Codex does not yet know about, but which should be configurable by the
command line as well? Let's say the new Loader uses a database and needs to
know the connection string for the database. To be able to configure the connection
string by the command line, the Loader must have a settter for that property,
e.g. setConnectionString(). If the loader has been initialized with the alias
"db", the property can be configured with:
Codex will first look for a configured element with the alias
"db" and then uses reflection to set the property. So it is quite
easy to add new components to Codex without having
to change the command line implementation. Let's continue with a full description
of the command line interface
This must be the first command line parameter, if the default
configuration shall not be used.
-o
--outdir
1
directory
the directory where all output files (with a relative path after the @document
pragma) will be written.
-cl
--classes
*
classSelection
the classes for which code should be generated. This can either be a single
fully qualified class name, or TODO
-m[:alias]
--model[:alias]
*
modelFile
A model file to be loaded. If the alias is given the Loader with this
alias is used (see Aliases
above).
-t
--templates
*
templateFiles
a list of template files (space separated)
--<alias>:<property>
*
value
setting any property of a previously registered component (see Aliases
above)
.p:suffix
--post:suffix
*
fully qualified class name of a class that implements the PostProcessor
interface
A post processor that should be used for post processing files (see Post
Processors). The suffix determines which files this post processor is
reponsible for
-l[:alias]
--loader[:alias]
*
class (fully qualified ) that implements the MetaClassLoader
interface
registers a new MetaClassLoader with Codex
(see Loader
).
-a
-aspects
*
list of (fully qualified) class es that implements the Aspectory
interface
Registes a new Aspectory with Codex. The
Alias property of the Aspectory will be used to register it.